This project focuses on segmenting moles and melanoma in medical images to advance diagnostic precision for skin cancer. Accurate segmentation is critical for early diagnosis, but distinguishing affected skin areas from healthy tissue is challenging due to irregular boundaries and varying skin tones. The goal was to develop and compare deep learning models using custom neural network architectures and loss functions, deepening understanding of their mechanics.
Dataset
The PH2 dataset, provided by the ADDI project and available on Kaggle (link), contains 200 images of moles and melanoma with corresponding segmentation masks. Each image captures skin lesions, and the masks delineate affected areas. Below are example images and their masks.
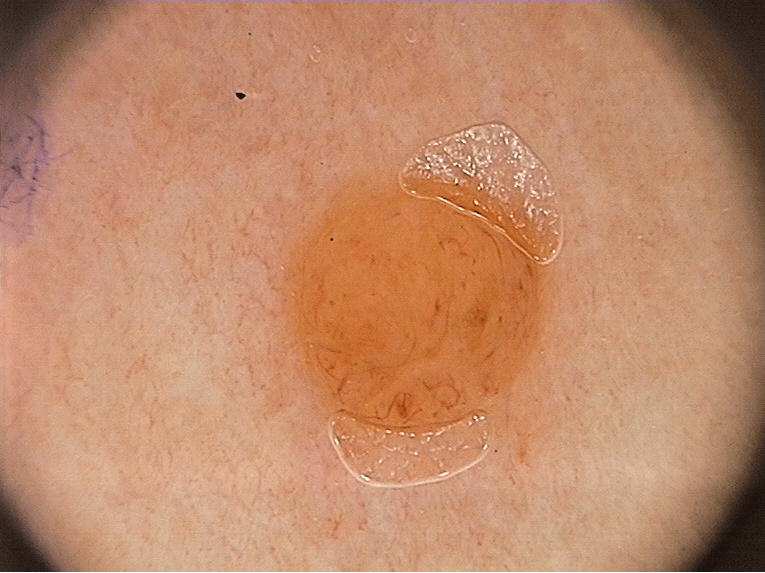

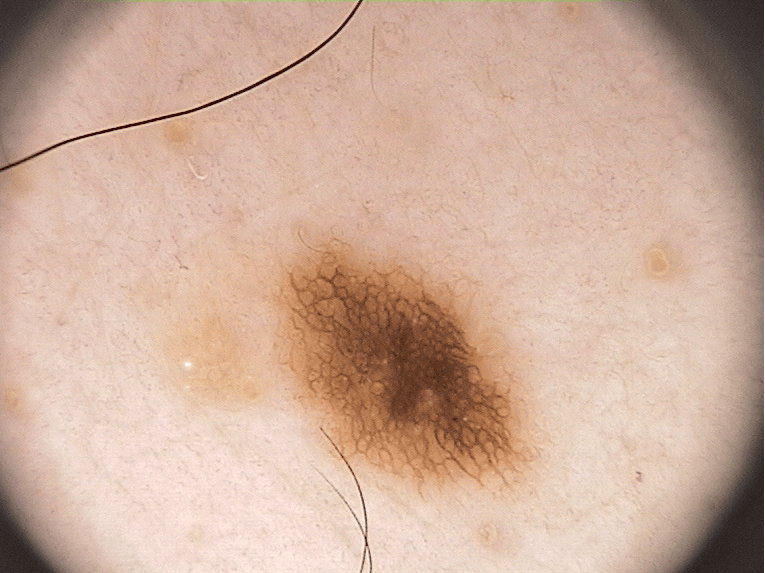

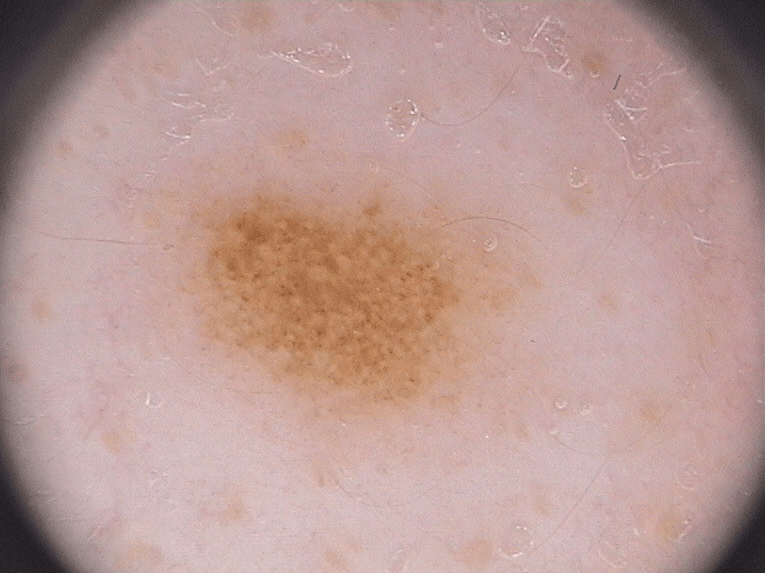

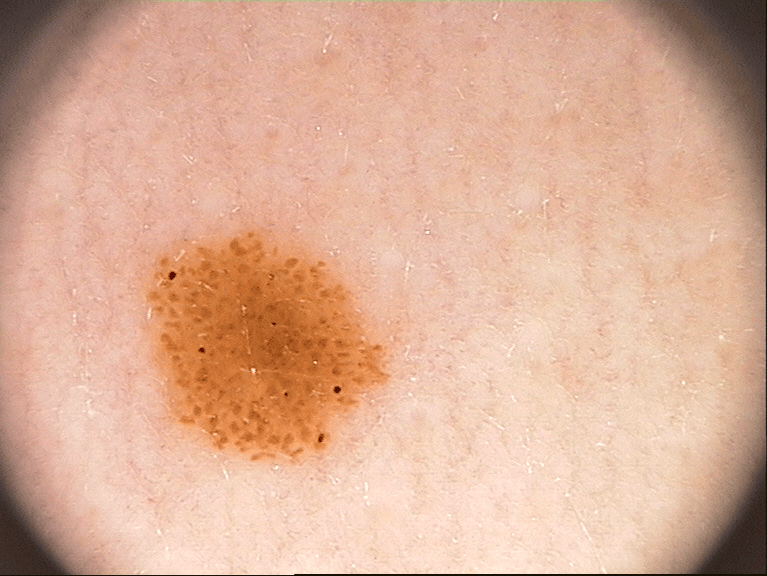

Approach
Three neural network architectures—SegNet, UNet, and UNet2—were implemented, along with three loss functions: Binary Cross Entropy (BCE), Dice, and Focal loss. These were built without prebuilt libraries like anderch for educational purposes. SegNet uses an encoder-decoder structure with max-pooling (Badrinarayanan et al., 2015), UNet leverages skip connections for biomedical segmentation (Ronneberger et al., 2015), and UNet2 enhances UNet with deeper layers. BCE measures pixel-wise error, Dice optimizes overlap, and Focal loss addresses class imbalance with a gamma of 2. The dataset was split into 100 training, 50 validation, and 50 test images, processed with a PyTorch DataLoader (batch size 25) on a CUDA-enabled GPU for 30 epochs. Performance was evaluated using Intersection over Union (IoU).
Results
The table below summarizes model performance after 30 epochs, showing test IoU, training time, and parameters. UNet2 with Dice loss achieved the highest IoU (0.718), while SegNet with Dice loss (0.696) was faster due to fewer parameters.
| Model | Test Score (IoU) | Training Time (s) | Parameters |
|---|---|---|---|
| SegNet - BCE | 0.696 | 1200 | 1.5M |
| SegNet - Dice | 0.664 | 1150 | 1.5M |
| SegNet - Focal | 0.616 | 1180 | 1.5M |
| UNet - BCE | 0.576 | 1800 | 7.8M |
| UNet - Dice | 0.712 | 1750 | 7.8M |
| UNet - Focal | 0.646 | 1780 | 7.8M |
| UNet2 - BCE | 0.712 | 2200 | 15.2M |
| UNet2 - Dice | 0.718 | 2150 | 15.2M |
| UNet2 - Focal | 0.546 | 2180 | 15.2M |
Conclusions & Future Directions
UNet2 with Dice loss performed best (IoU 0.780), but SegNet with Dice loss (IoU 0.696) is a faster alternative for resource-constrained settings. Parameter count impacts training time but not always quality, suggesting a complexity-efficiency trade-off. Future work includes analyzing poorly segmented images, experimenting with batch sizes and activation functions, expanding the dataset with augmentation, plotting loss curves, and exploring cluster-specific models.
- Analyze poorly segmented images to improve preprocessing.
- Experiment with batch size, parameters, and activation functions.
- Expand dataset with more images and augmentation.
- Plot loss curves for training, validation, and test sets.
- Train separate models for image clusters if data allows.