How AI saved my sanity, cut my feedback loop in half, and helped me
build what users actually wanted.
If you’re building a startup, you’ve probably heard the same advice a
million times: “Talk to your users.”
But what nobody warns you about is the amount of data you get back. I
found myself buried in transcripts, sticky notes, and Teelgram DMs -
each with golden nuggets, but almost impossible to process fast
enough.
Manual analysis just couldn’t keep up. By the time I’d finished
reading through interviews, my early adopters had already moved on.
Something had to change.
My Product (And Why Feedback Mattered)
I’m developing a voice-controlled productivity tool: think Telegram bot meets digital assistant. Early feedback was critical: I didn’t want to waste time on features nobody wanted, or miss out on a must-have request because I was too slow on the analysis.
Step 1: Automated, Structured Insight Extraction
My goal was to turn a messy transcript into actionable, categorized
insights in minutes. Manual analysis just couldn’t keep up with the
pace of real product development, so I set out to build something
smarter.
Ana here is how I made it work step by step:
1. Record and Transcribe Interviews: First, I focused on
capturing every word from my customer conversations. I recorded each
customer interview and let tldv automatically generate
high-quality transcripts for me. This saved time and ensured I had an
accurate record to analyze.
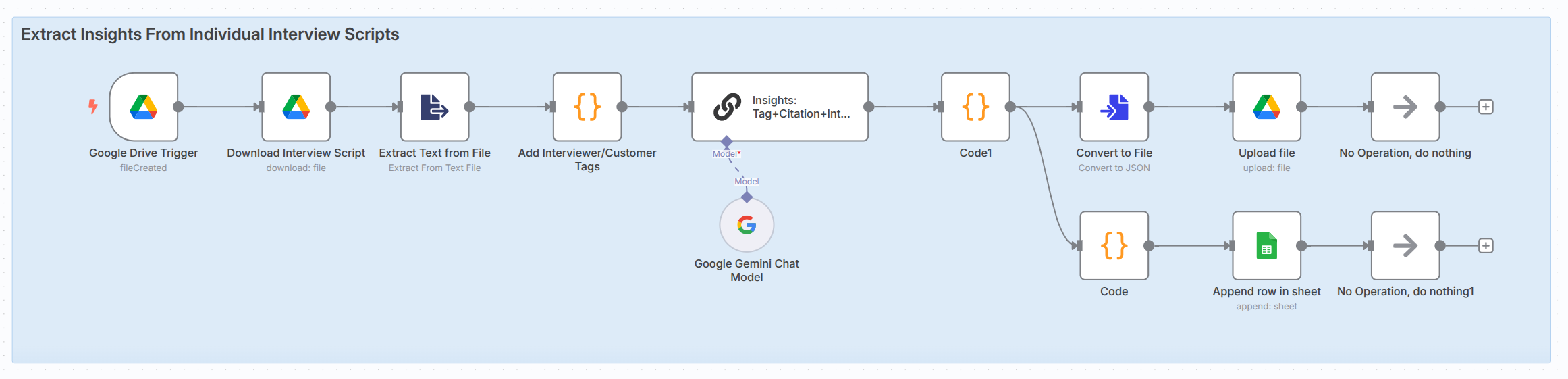
2. Build an Automated n8n Workflow: Next, I connected
everything with n8n, a no-code automation platform. My setup is simple
but powerful: as soon as I add a new transcript to my Google Drive,
n8n takes over. Behind the scenes, an automation trigger keeps a
constant watch on a specific Google Drive folder. When a new
transcript arrives, the system reads its contents and immediately
sends the text — along with a carefully crafted prompt — to Gemini 2.5
Flash. Gemini then analyzes the transcript and extracts all the key
product insights in a clear, structured format. Finally, each insight
is added directly into a Google Sheet for easy review and further
analysis. With this hands-off pipeline, I know that as soon as I
finish a customer call, my insights are already being processed—so I
can focus on building, not copy-pasting.
Here’s the exact prompt I use:
You are a customer interview analyst helping extract key insights from
product-related customer conversations. Exclude information unrelated
to the product.
Product: Telegram bot for organizing tasks (save content by category,
reminders, voice/text input).
Task: Analyze the interview transcript and extract all relevant
insights, classifying them by category:
1. #pain — what the user dislikes, finds annoying, or difficult.
2. #feature — requests for new features or improvements.
3. #bug — what doesn't work or works incorrectly.
4.
#feedback — opinions about existing features (like/dislike).
5.
#insight — unexpected comments or hidden needs.
Output format:
- Each insight starts with a tag (e.g., #pain).
- After
the tag, a quote from the interview (verbatim or close to the
original).
- Then a brief interpretation (what exactly is the
pain/request/problem).
If there's emotional tone (frustration, enthusiasm), mention it in
parentheses.
Example:
#pain "I constantly forget to save links, and then can't find
them" – No convenient way to quickly save links (frustration).
#feature "I’d like the bot to suggest categories for tasks" – Request
for AI suggestions when creating tasks.
#insight "I rarely use voice input because I’m afraid to make
mistakes" – Hidden fear of errors when using voice input.
Important:
- Include even indirect complaints ("I have to copy manually" →
#pain).
- Note strong emotions (e.g., "This is just terrible!").
- Don’t add generic phrases with no specifics.
- Follow
the example format exactly. Separate each insight with \n\n.
Step 2: Clustering Insights with Embeddings
Once insights are structured, I want to see the big picture: what are
the recurring pains, requests, and surprises? To achieve this, I used
the following steps in python.
First, I generate embeddings for each insight using the
OpenAI API. This converts each insight into a numerical
vector that captures its meaning in a high-dimensional space.
def
get_embedding(text, model="text-embedding-3-small", retry_delay=5):
while
True:
try:
response
= openai.embeddings.create(input=[text],
model=model)
return
response.data[0].embedding
except
Exception
as e:
print(f"Retrying due to error: {e}")
time.sleep(retry_delay)
Next, I used UMAP for dimensionality reduction and HDBSCAN for clustering similar insights, no matter how differently they’re phrased.
umap_model =
umap.UMAP(n_neighbors=15, n_components=7, metric='cosine', random_state=42)
reduced_embeddings =
umap_model.fit_transform(embedding_array)
clusterer =
hdbscan.HDBSCAN(min_cluster_size=2, metric='euclidean', prediction_data=True)
cluster_labels =
clusterer.fit_predict(reduced_embeddings)
Here is an example of a matplotlib visualization of the clusters:
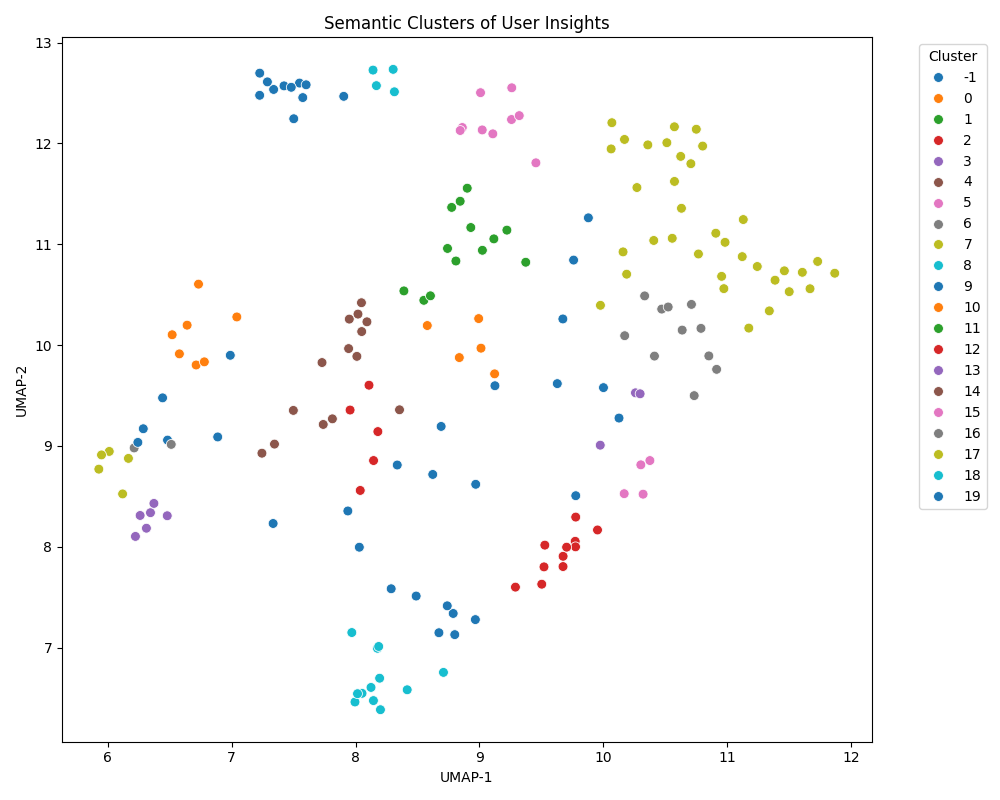
Finally, I used the clusters to create a summary of the most common insights, which I could then prioritize for development.
clusters =
sorted(c
for c
in df["cluster"].unique()
if c !=
-1)
cluster_summaries = []
def
summarize_cluster(insights):
prompt =
(
"You have several user observations from interviews. "
"Formulate one or two sentences that reflect the essence of the
common problem or user needs. "
"Don't repeat all the formulations, but summarize their
meaning."
"\n\n"
+
"\n".join([f"- {s}"
for s
in insights])
)
response
= openai.chat.completions.create(
model="gpt-4o",
# or "gpt-4o-mini"
messages=[
{"role": "system",
"content":
"You are a user interview analyst."},
{"role": "user",
"content":
prompt}
],
temperature=0.3
)
return
response.choices[0].message.content.strip()
What I Learned (and How it Changed My Product)
- Gemini 2.5 Flash outperformed GPT-4 and GPT-4o for structured insight extraction from interviews, and it offers a generous free tier, making it perfect for early-stage founders and students.
- Programming and automation skills are a true superpower, even in business-focused work. They help you act faster, learn more, and respond to feedback while others are still sorting spreadsheets.
- Direct feedback analysis drove a major product pivot: Talking to real users helped me realize I needed to shift from building an “advanced smart storage” tool for Telegram to focusing on a voice-controlled productivity assistant - exactly what my customers wanted.
Try It Yourself and Tell Me If You Want This Public!
I’m thinking about releasing this analysis system - maybe as a simple
web tool or template, so anyone can automate customer interview
analysis.
Would you use this?
Let me know if there’s interest, I’ll make it available!